[GitPulse #5] 허수 커밋 식별을 위한 점수제 도입 & API 페이징 최적화

✅ 오늘의 목표
- 허수 커밋 탐지를 위한 로직 구현
- 커밋 API 호출 시 기간 필터 적용
- PR 리스트 UI 개선 및 기능 추가
🧩 문제 상황 / 배경
팀 프로젝트에서 Git 커밋 히스토리를 깔끔하게 관리하는 것은 협업 효율성과 코드 품질 향상에 매우 중요합니다.
하지만 종종console.log추가, 불필요한 주석 수정 등 의미 없는 ‘허수 커밋’ 들이 히스토리를 흐트러뜨리는 문제가 있었습니다. 이를 해결하기 위해 다음과 같은 개선이 필요했습니다:
- 커밋 메시지, 변경 파일 수, 라인 수 등을 기준으로 특정 커밋을 허수로 판단하고 UI에 시각화해 보여줍니다.
또한 기존 커밋 API는 기본 호출 시 최대 30개의 데이터만 제공되어, 원하는 기간의 모든 커밋을 불러오지 못하는 문제가 있었습니다.
- 이를 해결하기 위해 기간 필터링 기능과 데이터 호출 최적화가 필요했습니다.
🛠️ 해결 과정 / 코드 정리
🔸 허수 커밋 필터링 로직
1. 첫 번째 시도: 단순 조건 필터링
초기 아이디어는 몇 가지 단순한 규칙을 기반으로 의심스러운 커밋을 식별했다.
초기 규칙 :
- 커밋 메시지가 10자 미만 -
shortMessage - 코드 변경량(추가+삭제)이 10줄 미만 -
smallChange - 변경된 파일이 1개 이하 -
singleFile - 변경 내용에
console.log만 존재 -onlyConsole - 변경된 파일이 코드 파일이 아님 -
nonCodeFilesOnly
이 규칙 중 하나라도 해당하면 ‘의심스러운 커밋’으로 분류했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 첫번째 시도 - 일부 로직
const shortMessage = message.length < 10;
const smallChange = additions + deletions < 10;
const singleFile = files.length <= 1;
const onlyConsole = files.every((file) =>
file.patch?.replace(/\s/g, "").includes("console.log")
);
const nonCodeFilesOnly = files.every((file) =>
/\.(md|json|yml|lock|env|txt)$/i.test(file.filename)
);
const reasons = [];
if (shortMessage) reasons.push("짧은 메시지");
if (smallChange) reasons.push("변경량 적음");
// ...
// reasons 배열에 내용이 하나라도 있으면 의심 커밋으로 간주
const isSuspicious = reasons.length > 0;
❗ 문제점
- 성능 저하 : 분석할 커밋 목록 전체(수백 개)에 대해 하나씩 상세 정보를 요청(API call)하다 보니, 모든 커밋을 분석하는 데 시간이 매우 오래 걸림.
- 낮은 정확도 : 단순한 조건 중 하나만 맞아도 ‘의심’으로 판단하니, 실제로는 문제가 없는 커밋까지 필터링되는 ‘False Positive’가 너무 많음. (예: 중요한 설정 파일 1개만 수정해도 ‘파일 1개’, ‘변경량 적음’ 조건에 걸림)
- 복잡한 UI : 왜 의심스러운지 여러 이유를 UI에 나열하기가 지저분했고, 이는 결국 UX의 질을 떨어뜨림.
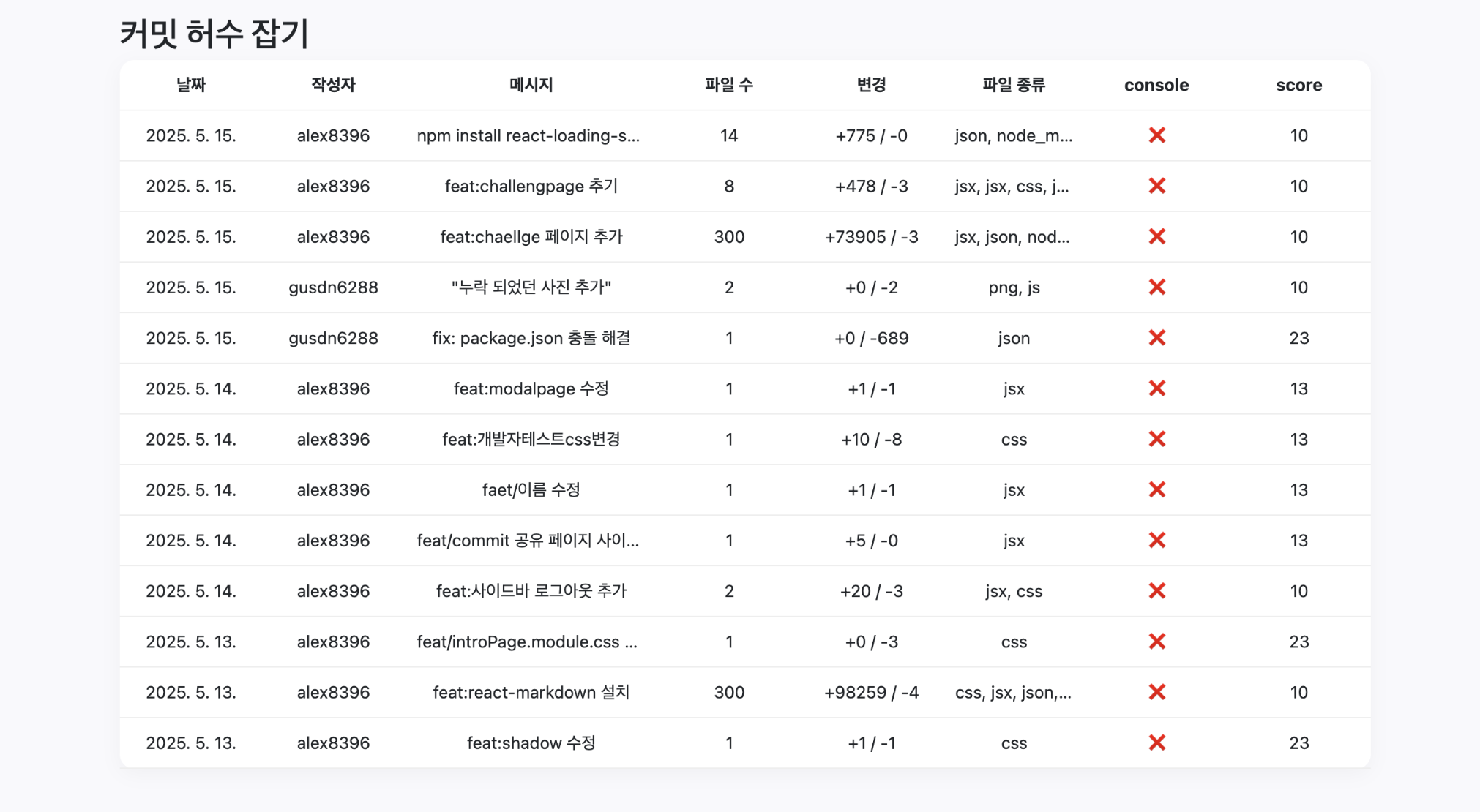
2. 해결책: 점수제 기반의 정량적 평가 도입
이러한 문제들을 해결하기 위해, 단순한 ‘참/거짓’ 판별이 아닌, 각 항목에 가중치를 부여하는 ‘점수제’를 도입해 로직을 개선함.
주요 개선 사항:
- 분석 대상 최적화: 전체 커밋이 아닌, ‘최근 2주’간의 커밋 최대 50개만 가져오도록 API 호출을 변경하여 성능 문제를 해결
- 임계값 설정: 계산된 총점이 미리 설정한 기준(5점)을 넘을 경우에만 ‘의심 커밋’으로 최종 판단하여 정확도를 높임
- 점수제 도입: 각 조건의 중요도에 따라 다른 점수를 부여
| 조건 | 점수 | 사유 설명 |
|---|---|---|
| 커밋 메시지 6자 미만 | 3점 | 너무 짧아 의미 파악이 어려움 |
| 전체 변경량 6줄 미만 | 10점 | 실제 코드 수정이 거의 없음 |
| 파일 변경 수 1개 이하 | 3점 | 작은 변경으로는 허수 가능성 존재 |
| console.log만 포함한 경우 | 10점 | 의미 없는 로그만 포함된 커밋 |
| 코드 파일이 전혀 없는 경우 | 10점 | 비코드 파일만 수정된 커밋 |
개선된 로직
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
export const useSuspiciousCommits = ({ name, repo }) => {
// ... state 설정 ...
useEffect(() => {
const fetchSuspicious = async () => {
// 1. 분석 대상 최적화: 최근 2주, 최대 50개 커밋
const since = new Date(Date.now() - 14 * 24 * 60 * 60 * 1000).toISOString();
const commits = await fetchWithToken(
`/repos/${name}/${repo}/commits?since=${since}&per_page=50`
);
// ...
for (const commit of commits) {
// ... 상세 정보 조회 ...
let score = 0;
const reasons = [];
// 2. 점수제 도입
if (message.length < 6) {
score += 3;
reasons.push("커밋 메세지가 너무 짧습니다.");
}
if (additions + deletions < 6) {
score += 10;
reasons.push("변경량이 적습니다.");
}
if (files.length <= 1) {
score += 3;
reasons.push("파일 1개만 변경되었습니다.");
}
// ... (console.log, 비코드 파일 등 다른 조건 점수 추가)
// 3. 임계값 설정
if (score >= 5) {
results.push({
// ... 커밋 정보 ...
score,
reasons,
isSuspicious: true,
});
}
}
setSuspiciousCommits(results);
setLoading(false);
};
fetchSuspicious();
}, [name, repo]);
return { suspiciousCommits, loading };
};
🔸안정적인 렌더링을 위한 방어 코드: PRList?.map vs Array.isArray(PRList)
변경 전 - 옵셔널 체이닝 (?.) 사용
초기 코드는 null이나 undefined일 경우를 대비해 옵셔널 체이닝 연산자를 사용
1
2
3
4
5
6
7
8
9
10
11
12
{PRList?.map((PR, index) => (
<tr key={index}>
<td className={css.colTitle}>
<a className={css.prLink}>{PR.title}</a>
</td>
<td className={css.colStars}>{PR.user.login}</td>
<td className={css.colCreated}>
{PR.created_at.split("T")[0]}
</td>
{/* ... */}
</tr>
))}
✅ 변경 후 - Array.isArray()도입으로 런타임 안정성 확보
안정성을 높이기 위해 Array.isArray()를 사용한 조건부 렌더링으로 코드를 수정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{Array.isArray(PRList)
? PRList.map((PR, index) => (
<tr key={index}>
<td className={css.colTitle}>
<a className={css.prLink}>{PR.title}</a>
</td>
{/* ... */}
<td className={css.colReview}>
<button onClick={() => handlePrComment(PR.number, PR.url)}>
Review
</button>
</td>
</tr>
))
: null}
✅ 왜 Array.isArray(PRList)로 바꿨을까?
1. 보다 명시적인 타입 체크
PRList?.map(...)는 PRList가null이나undefined가 아니면 map을 실행한다.- 하지만
PRList가 정의는 되어 있는데 배열이 아닐 경우 (예: 객체, 숫자 등)에도 오류 없이 넘어가지만, 실행 중map is not a function에러가 발생할 수 있다. Array.isArray(PRList)는 실제로 PRList가 배열인지 명확히 체크합니다.👉 즉, 런타임 오류 방지를 위한 보다 안정적인 타입 검증 !!
2. 초기 데이터 상태 대응
- API 통신 결과로
PRList가 아직 배열로 세팅되지 않았을 때,null이거나{} (object)일 수 있다. - 이때
Array.isArray()로 확인하면 렌더링 에러 없이 안전하게 통제
- PRList가 실제 배열인지 확인하기 위함 (보다 정확한 조건문)
- map is not a function 에러 방지
- 초기값이나 오류 상황에서도 안전한 렌더링을 위함
🔸 필요한 데이터를 정확히 가져오는 API 최적화
주간 단위로 커밋 데이터를 분석해야 하는데, 기본 API 호출로는 제한된 개수의 커밋만 불러올 수 있었습니다.
변경 전의 문제점: 불충분한 데이터
기존 코드는 GitHub API를 기본값으로 호출했습니다.
1
2
3
4
5
6
7
8
9
// 조직 repo 불러오기
export const getOrgsRepos = async (orgs, repo) => {
try {
const res = await axios.get(`${BASE_URL}/repos/${orgs}/${repo}/commits`);
return res.data;
} catch (error) {
console.log("조직 정보 가져오기 실패", error);
}
};
이 방식의 가장 큰 문제는, GitHub API가 기본적으로 최근 커밋 30개만 반환한다는 점입니다.
활발한 프로젝트에서는 하루만에도 수십 개의 커밋이 쌓일 수 있어, 30개라는 양은 주간 분석을 하기에는 턱없이 부족했습니다.
변경 후: 원하는 기간의 충분한 데이터 확보
이 문제를 해결하기 위해 조회 기간을 명시하고, 페이지네이션을 활용하여 한 번에 더 많은 데이터를 가져오도록 로직을 변경했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
export const getOrgsRepos = async (orgs, repo) => {
try {
// 1. 조회 기간 설정 (오늘 포함 최근 7일)
const now = new Date(); // 현재 시각
const since = new Date(now);
since.setDate(now.getDate() - 6); // 6일 전(오늘 포함해서 7일간)
since.setHours(0, 0, 0, 0); // 00:00:00.000으로 맞춤
const until = new Date(now);
until.setHours(23, 59, 59, 999); // 오늘 23:59:59.999까지
const sinceStr = since.toISOString();
const untilStr = until.toISOString();
// 2. Promise.all로 커밋(최대 200개)과 PR을 동시에 요청
const [commitsPage1, commitsPage2, pulls] = await Promise.all([
// 3. per_page와 page 파라미터로 충분한 데이터 확보
fetchWithToken(
`/repos/${orgs}/${repo}/commits?since=${sinceStr}&until=${untilStr}&per_page=100&page=1`
),
fetchWithToken(
`/repos/${orgs}/${repo}/commits?since=${sinceStr}&until=${untilStr}&per_page=100&page=2`
),
fetchWithToken(`/repos/${orgs}/${repo}/pulls`),
]);
const commit = [...commitsPage1, ...commitsPage2]; // 200개로 병합
return {
commit,
pulls,
};
} catch (error) {
console.log("조직 repo 가져오기 실패", error);
throw error;
}
};
✅ 무엇이 개선되었을까?
- 데이터의 충분성 확보:
per_page=100과 page 파라미터를 이용해 최대 200개의 커밋을 가져올 수 있어, 기본 30개 제한으로 인한 데이터 누락 문제를 해결 - 데이터의 정확성 향상: since와 until 파라미터로 ‘최근 1주일’이라는 명확한 시간 범위를 지정하여, 분석에 필요한 데이터만 정확하게 타겟팅
- 응답 속도 개선:
Promise.all을 사용해 여러 API 요청을 병렬로 처리함으로써, 전체 데이터 수신 시간을 단축
✅ 결과 및 느낀 점
- 단순 조건 기반 필터링은 한계가 있었고, 정량적 점수 기준을 도입하면서 정확도와 UX가 크게 향상되었다.
- GitHub API의 한계를 체감하며 필터링 및 데이터 수집 로직의 중요성을 깨달았다.
🖼️ 작업 결과물
Reference
이 포스트는 아래 게시글의 정보 및 이미지가 사용되었습니다.
- GitHub REST API - Commits
- GitHub REST API - Repos
- MDN Web Docs - Array.isArray()
- MDN Web Docs - Optional chaining (?.)