[Day16] Algorithm - Sort
[Day16] Algorithm - Sort
알고리즘
- 문제를 해결하기 위해 수행해야 하는 절차나 방법
- APS (Algorithm Problem Solving) : 알고리즘 문제 풀이
알고리즘의 필요성
예를 들어, 1부터 100까지의 합을 구하는 문제를 생각해 보자
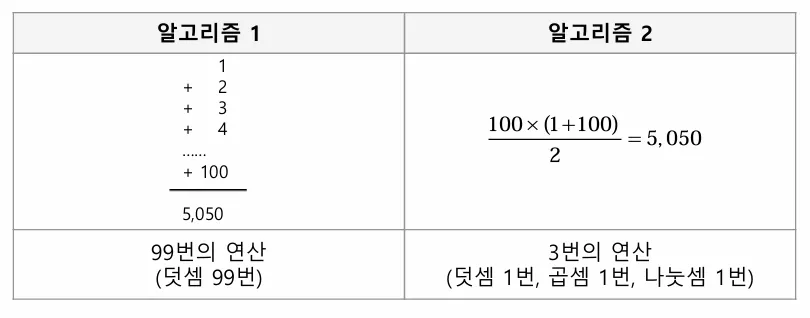
문제를 푸는 방식에 따라 작업량이나 소요시간 등이 달라질 수 있다.
고려 사항
- 정확성 : 얼마나 정확하게 동작하는가
- 작업량 : 얼마나 적은 연산으로 원하는 결과를 얻어내는가
- 메모리 사용량 : 얼마나 적은 메모리를 사용하는가
- 단순성 : 다른 사람이 이해하기 쉬운가
- 최적성 : 더 이상 개선할 여지없이 최적화되었는가
알고리즘을 표현하는 두 가지 방법
의사코드

순서도
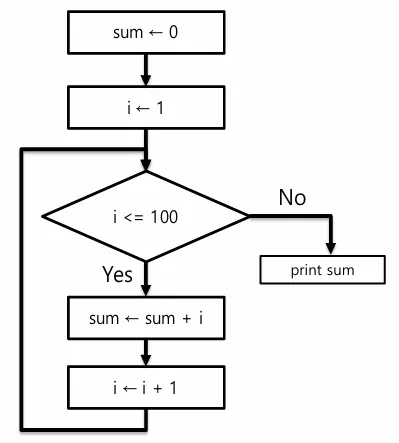
시간복잡도 : 알고리즘의 효율성을 평가하는 지표중 하나
실제 수행 시간이나 실행되는 명령문의 개수를 계산 
빅오 표기법
- 시간복잡도 함수 중에서 가장 큰 영향력을 주는 n에 대한 항만을 표시
- 계수(Coefficient)는 생략하여 표시

✅ Big O 시간 복잡도는 요소 수(n)이 증가함에 따라 다음과 같은 연산수의 증가를 보인다 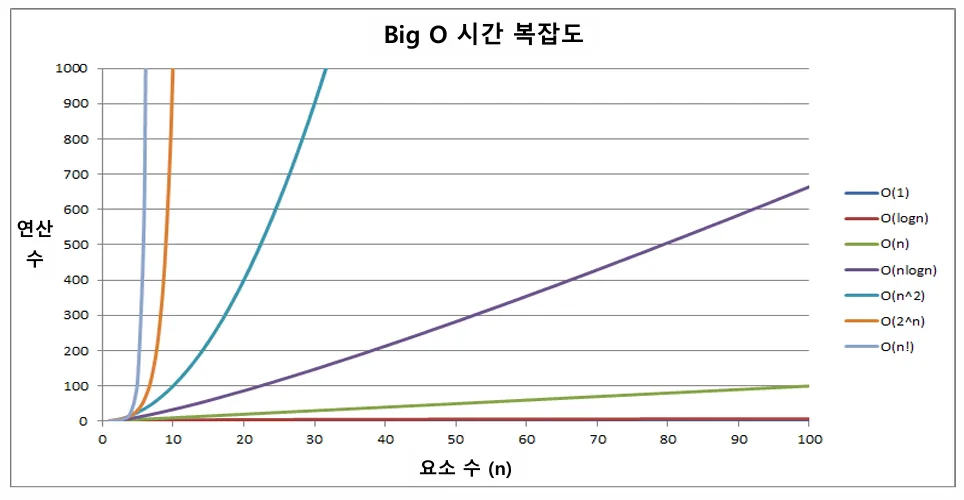
시간 복잡도에 따른 n의 가용 범위
| 시간 복잡도 | n의 가용 범위 |
|---|---|
| O(n!) | 10 |
| O(2^n) | 20~25 |
| O(n^3) | 200~300 |
| O(n^2) | 3000~5000 |
| O(nlogN) | 100만 |
| O(n) | 1000만~2000만 |
| O(logN) | 10억 |
✅ n에 따른 실제 실행 시간 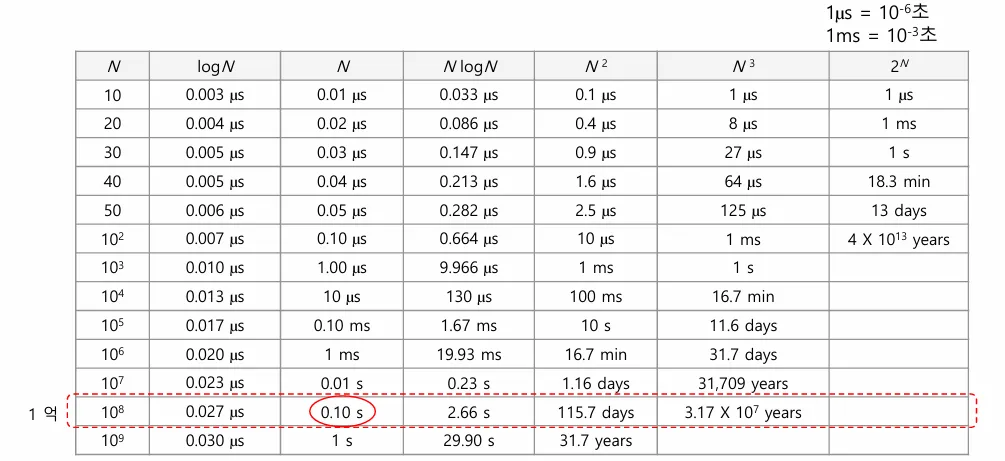
자료 구조와 APS(알고리즘 문제 풀이)의 관계
- 정의 : 데이터를 효율적으로 다루는(CRUD) 방법을 정의한 것
- 프로그램의 목적에 따라 활용할 수 있는 자료구조가 다양함
- ex) Array, List, Stack, Queue, Tree…
- 효율적인 알고리즘을 구현하기 위해서는 효율적인 자료구조 선택이 필수
알고리즘 이론 - 정렬
버블 정렬 (Bubble Sort)
- 인접한 두 요소를 비교 → 큰 값을 뒤로 보냄 → 반복
- 한 번의 사이클이 끝나면 가장 큰 값이 맨 뒤에 위치
- 정렬 과정
- 첫 번째 원소부터 인접한 원소와 비교하여 자리를 교환해가면서 마지막 자리까지 이동한다
- 기준(오름차순)한 사이클이 끝나면 가장 큰 원소가 마지막 자리로 위치하게 된다
- 교환하며 자리를 이동하는 모습이 물 위에 올라오는 거품 모양과 같다고 하여 버블 정렬이라고 한다
- 시간복잡도 : O(n^2) -> n이 5000이하일 때 사용하자


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import java.util.Arrays;
public class BubbleSort {
public static void main(String[] args) {
int[] arr = {55,7,78,12,42};
int n = arr.length;
for (int i = n - 1; i > 0; i--) { //i값이 j의 비교 기준이 되기 위해 배열length부터 시작해서 0으로 감소하는 반복이 유리하다
for (int j = 0; j < i; j++) { //현재 행(i)의 끝 열(j)이 i값보다 작을 때 까지만 반복하면 된다
if (arr[j] > arr[j + 1]) { // 뒤에 있는 숫자보다 내가 크면
// Swap arr[j] and arr[j+1]
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp; // 내가 뒤로 간다
}
}
}
// Arrays.toString()을 사용하여 출력
System.out.println(Arrays.toString(arr));
}
}
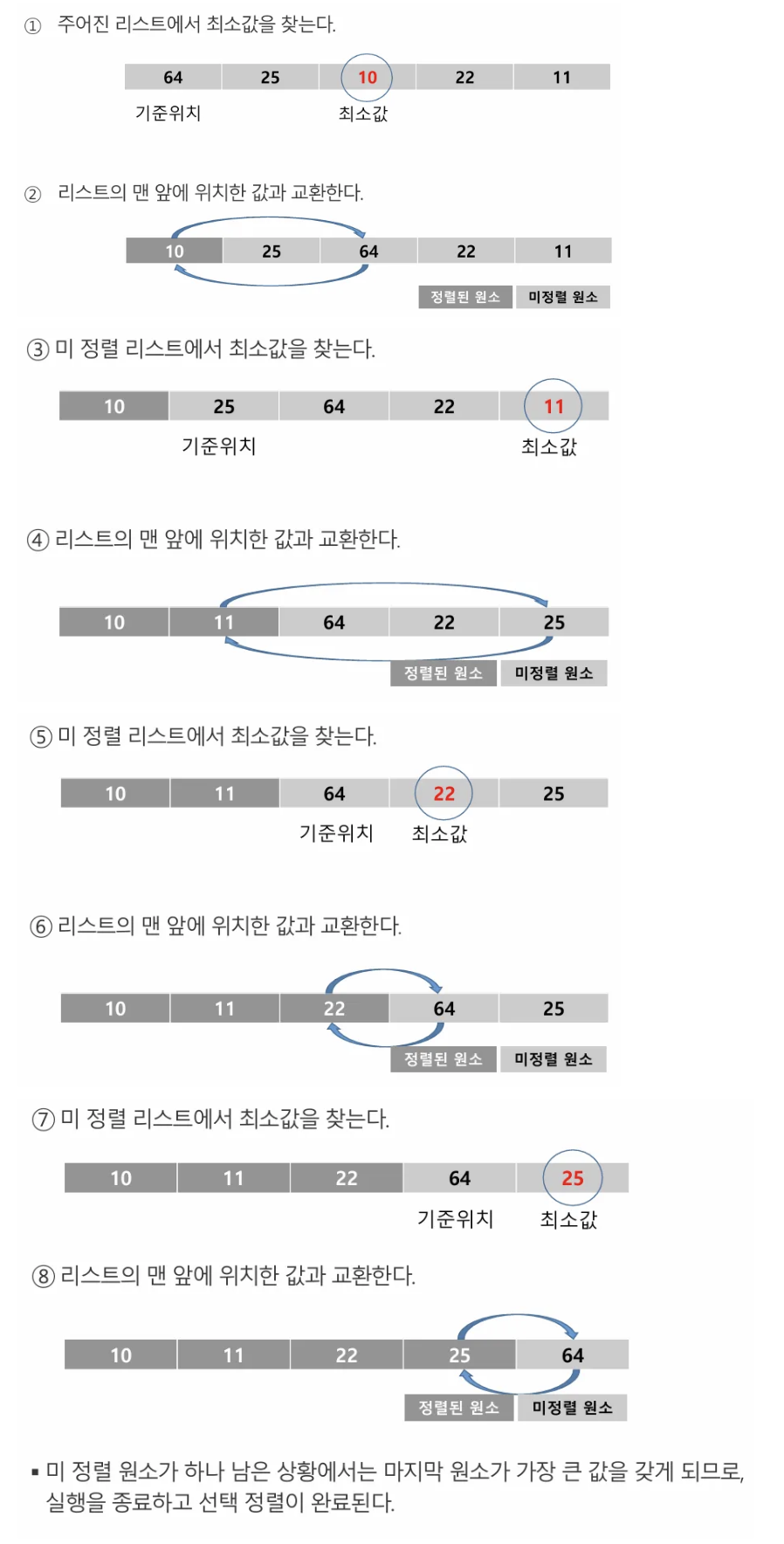
선택정렬 (Selection Sort)
- 저장되어 있는 자료 중에서 원하는 항목을 찾는 작업
- 비교 횟수는 많지만, 교환 횟수는 적음
- 정렬 과정 (ex. 주어진 자료들 중 세 번째로 작은 값 찾기)
- 주어진 자료들 중 최소값을 찾는다
- 그 값을 리스트의 맨 앞에 위치한 값과 교환한다
- 맨 처음 위치를 제외한 나머지 리스트를 대상으로 위의 과정을 반복한다
- 시간복잡도 : O(n^2)

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
//주어진 자료들 중 세 번째로 작은 값 찾기
import java.util.Arrays;
public class ThirdSmallestExample {
public static void main(String[] args) {
int[] nums = {64, 25, 10, 22, 11}; // 정렬할 배열
int n = nums.length; // 배열의 길이
// 선택 정렬을 사용하기 위해
int[] sortedNums = Arrays.copyOf(nums, n); // 원본 배열을 복사. 나중에 원본배열의 인덱스로 답을 내야 하므로
for (int i = 0; i < n - 1; i++) { //맨 앞을 빼고 돌면되니 n-1
int minIdx = i; // 현재 인덱스의 값을 최소값으로 가정
for (int j = i + 1; j < n; j++) { // 그 옆의 값들을 순회하면서
if (sortedNums[minIdx] > sortedNums[j]) {//가정한 값과 비교해서
minIdx = j; // 더 작은 값의 인덱스를 찾음
}
}
// 최소값이 현재 인덱스와 다르면 스와프
if (minIdx != i) {
int temp = sortedNums[i];
sortedNums[i] = sortedNums[minIdx];
sortedNums[minIdx] = temp;
}
} // 이 for문을 마치면 sortedNums 배열은 오름차순 정렬 완성
int thirdSmallest = sortedNums[2];// 세 번째로 작은 수를 찾아서
// 원본 배열에서 세 번째로 작은 수의 인덱스 찾기
// 요구사항이 세 번째로 작은 값을 출력하는 게 아니라 세 번째로 작은 값의 인덱스를 원본 배열에서 알아내는 것이므로.
int indexOfThirdSmallest = -1; // 답이 될 인덱스 초기화 (배열의 인덱스가 될 수 없는 값으로 초기화하는 게 좋음)
for (int i = 0; i < n; i++) {
if (nums[i] == thirdSmallest) {//원본 배열을 순회하며 thirdSmallest값을 찾아서
indexOfThirdSmallest = i; // 찾은 인덱스를 저장
break; // 찾았다면 그만 돌자
}
}
// 결과 출력
System.out.println("세 번째로 작은 수: " + thirdSmallest);
System.out.println("세 번째로 작은 수의 원본 배열 인덱스: " + indexOfThirdSmallest);
}
}
🚀 더 효율적인 방법 : Arrays.sort()를 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import java.util.Arrays;
import java.util.HashMap;
public class ThirdSmallestIndexExample {
public static void main(String[] args) {
int[] nums = {64, 25, 10, 22, 11}; // 정렬할 배열
int n = nums.length; // 배열의 길이
// 원본 배열의 인덱스를 저장할 HashMap
HashMap<Integer, Integer> indexMap = new HashMap<>();
for (int i = 0; i < n; i++) {
indexMap.put(nums[i], i); // 값과 인덱스를 저장 ( 배열은 인덱스가 키가 되는데 비해 값을 키로 삼아서 해당 값의 인덱스를 찾으려는 아이디어. 중복값이 없다는 조건이 필요함.)
}
// 배열 정렬
Arrays.sort(nums); //O(nlogn)으로 돌아간다
// 세 번째로 작은 수
int thirdSmallest = nums[2];
// 원본 배열에서 세 번째로 작은 수의 인덱스 찾기
int indexOfThirdSmallest = indexMap.get(thirdSmallest);
}
}
1
2
3
4
5
선택 정렬(Selection Sort)은 두 개의 중첩된 루프를 사용하여 배열의 모든 요소를 비교하면서 정렬하기 때문에 시간복잡도가 O(n²)입니다.
반면, Arrays.sort() 메서드는 내부적으로 Merge Sort 또는 Tim Sort(상황에 따라 다름)를 사용하여 정렬을 수행하며, 시간복잡도는 O(n log n)으로 더 효율적입니다.
즉, 배열이 클수록 Arrays.sort()를 사용하는 것이 훨씬 빠르며, 선택 정렬은 작은 배열에서만 고려하는 것이 좋습니다.
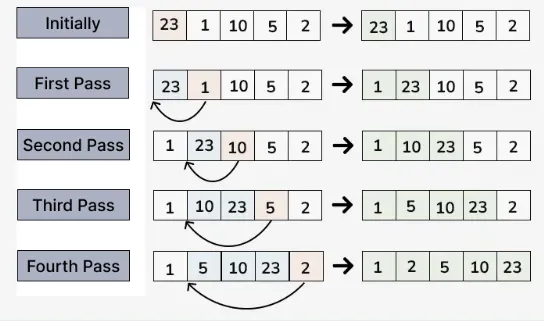
삽입 정렬 (Insertion Sort)
- 정렬할 요소를 뒤에 있는 요소와 비교한 뒤 스왑이 일어났다면 앞에 있는 모든 요소와도 비교를 하는 방식
- 정렬 과정
- 배열의 첫 번째 요소는 이미 정렬된 상태라고 가정
- 배열의 두 번째 요소(key)부터 시작하여 앞 칸의 요소가 더 크면 스왑
- 이것을 맨 앞 요소까지 반복한다
- 2~3번 반복
- 시간 복잡도 : O(n^2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import java.util.Arrays;
public class InsertionSort {
public static void main(String[] args) {
int[] arr = {23, 1, 10, 5, 2}; // 정렬할 배열 초기화
// 배열의 두 번째 요소부터 시작
for (int i = 1; i < arr.length; i++) {
int key = arr[i]; // 현재 비교할 요소(기준)
int j = i - 1; // 앞쪽 정렬된 부분의 마지막 인덱스
// key(기준)보다 큰 요소들을 오른쪽으로 이동
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j]; // 요소를 오른쪽으로 이동
j--;
}
arr[j + 1] = key; // key를 적절한 위치에 삽입
}
System.out.println(Arrays.toString(arr));
}
}
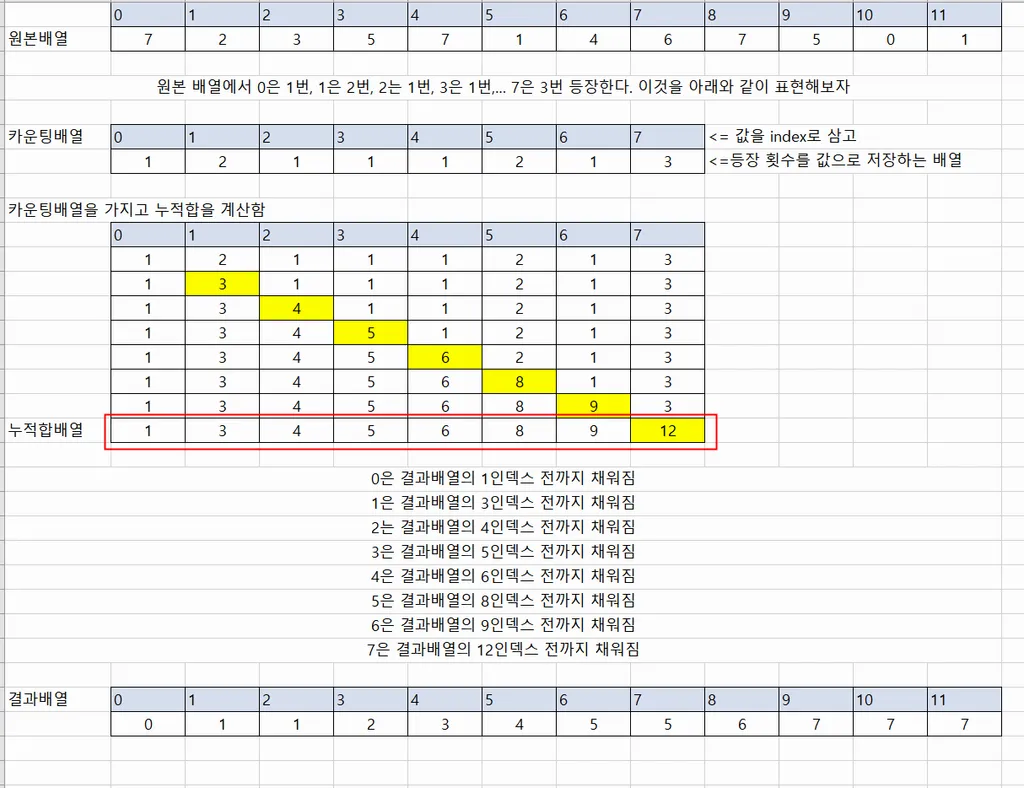
카운팅 정렬 (Counting Sort)
- 숫자의 개수를 세서 새로운 배열(count 배열)에 저장 → 누적합을 계산 → 정렬
- 정렬 과정
- 원본 배열에서 요소가 몇번 등장하는지를 count 배열이라는 새로운 배열에 저장한다. 이때 원본배열의 요소가 카운팅 배열의 인덱스가 되게 한다.
- 카운팅 배열을 가지고 누적합을 계산한다.
- 완성된 누적합 배열을 가지고 결과 배열을 생성한다.
- 시간복잡도 : O(n)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import java.util.Arrays;
public class CountingSortExample {
public static void main(String[] args) {
int[] arr = {7, 2, 3, 5, 7, 1, 4, 6, 7, 5, 0, 1};
int max = 7; // 배열의 최대값
int[] count = new int[max + 1];
int[] result = new int[arr.length];
// 각 숫자의 개수를 세기
for (int num : arr) {
count[num]++;
}
// 누적합을 구하여 count 배열을 수정하기
for (int i = 1; i <= max; i++) {
count[i] += count[i - 1];
}
// 결과 배열에 정렬된 값 넣기
for (int i = arr.length - 1; i >= 0; i--) {
result[count[arr[i]] - 1] = arr[i];
count[arr[i]]--;
}
}
}
✅ 시간복잡도가 획기적임에도 많이 쓰이지 않는 이유는?
- 요소의 값이 크면 count배열의 크기도 커지므로 메모리 낭비가 심할 수 있음
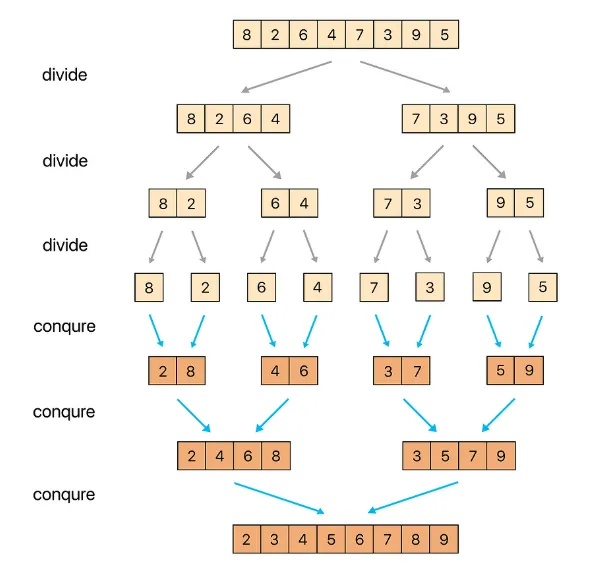
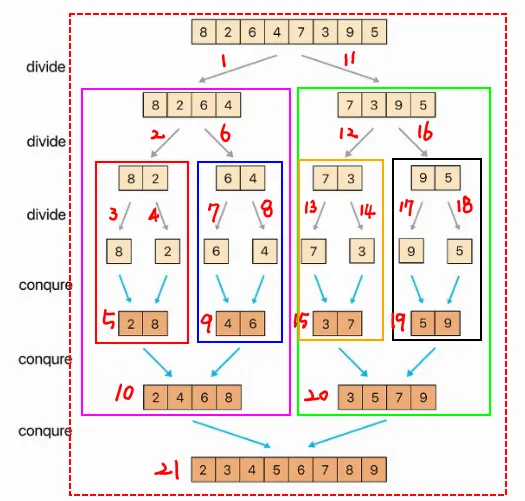
병합 정렬 (Merge Sort)
- 분할 정복 알고리즘
- 안정 정렬이며, 큰 데이터에서도 일정한 성능을 유지하지만, 추가적인 메모리 공간이 필요함.
- 정렬 과정
- 배열을 최소 단위까지 나눈다.
- 나눈 요소들을 병합하면서 정렬한다.
- 시간복잡도 : O(n log N)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import java.util.Arrays;
public class MergeSort {
// 배열을 병합 정렬하는 메서드
public static void divide(int[] array) {
// 배열의 길이가 2보다 작으면 정렬할 필요 없음
if (array.length < 2) {
return;
}
// 배열을 반으로 나누기
int mid = array.length / 2;
int[] left = Arrays.copyOfRange(array, 0, mid); // 왼쪽 부분 배열
int[] right = Arrays.copyOfRange(array, mid, array.length); // 오른쪽 부분 배열
// 왼쪽과 오른쪽 부분 배열을 재귀적으로 나눔
divide(left);
divide(right);
// 왼쪽과 오른쪽 배열을 병합
mergeSort(array, left, right);
}
// 두 개의 배열을 병합하면서 정렬하는 메서드
private static void mergeSort(int[] array, int[] left, int[] right) {
int i = 0, j = 0, k = 0; // 인덱스 초기화
//i는 left배열의 index, j는 right배열의 index, k는 원본배열의 index
// 두 배열에서 요소를 비교하여 작은 값을 원래 배열에 추가
while (i < left.length && j < right.length) {
if (left[i] <= right[j]) {
array[k++] = left[i++]; // 왼쪽 배열의 요소가 작으면 추가
} else {
array[k++] = right[j++]; // 오른쪽 배열의 요소가 작으면 추가
}
}
// 왼쪽 배열에 남은 요소가 있다면 추가
while (i < left.length) {
array[k++] = left[i++];
}
// 오른쪽 배열에 남은 요소가 있다면 추가
while (j < right.length) {
array[k++] = right[j++];
}
}
public static void main(String[] args) {
int[] array = {38, 27, 43, 3, 9, 82, 10}; // 정렬할 배열
System.out.println("정렬 전: " + Arrays.toString(array)); // 정렬 전 배열 출력
divide(array);
System.out.println("정렬 후: " + Arrays.toString(array)); // 정렬 후 배열 출력
}
}
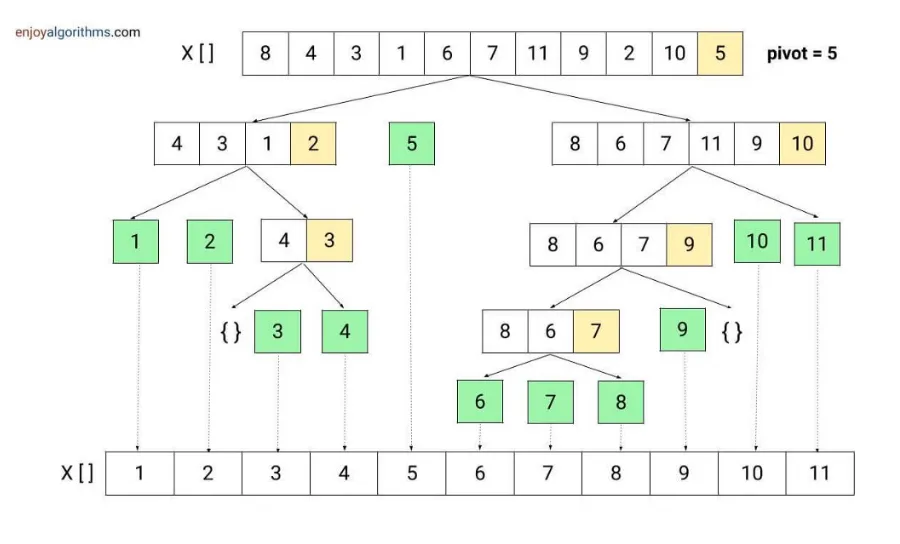
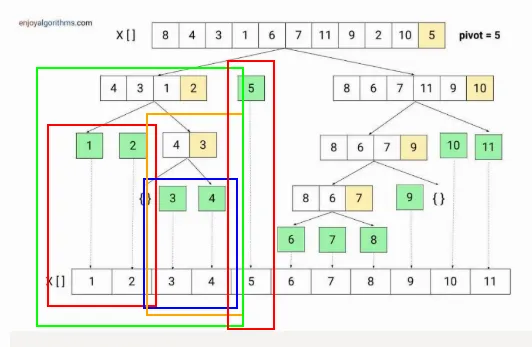
퀵 정렬 (Quick Sort)
- 분할 정복 알고리즘
- 정렬 과정
- 배열에서 하나의 요소를 피벗으로 선택한다.(보통 배열의 마지막 요소)
- 피벗보다 작은 요소는 왼쪽, 큰 요소는 오른쪽으로 정렬.
- 각 부분 배열을 재귀적으로 정렬.
- 배열의 크기가 1이 되면 정렬이 완료된 것으로 간주
- 시간복잡도: 평균 O(n log n), 최악 O(n²) (불균형한 경우)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
public class QuickSort {
// 퀵 정렬 메서드
public static void quickSort(int[] array, int low, int high) {
// low가 high보다 작을 때만 정렬 진행
if (low < high) {
// 파티션을 나누고 피벗의 인덱스를 반환
int pivotIndex = partition(array, low, high);
// 피벗을 기준으로 왼쪽과 오른쪽 부분 배열에 대해 재귀적으로 정렬
quickSort(array, low, pivotIndex - 1); // 왼쪽 부분 배열
quickSort(array, pivotIndex + 1, high); // 오른쪽 부분 배열
}
}
// 파티션 메서드
private static int partition(int[] array, int low, int high) {
int pivot = array[high];// 배열의 마지막 요소를 피벗으로 선택
int i = low - 1; // 피벗보다 작은 요소들의 마지막 인덱스.처음엔 없으므로 -1
// low부터 high-1까지 반복 (high는 피벗이므로 high-1까지)
for (int j = low; j < high; j++) {
if (array[j] < pivot) {// 현재 요소가 피벗보다 작으면
i++; // 작은 요소들의 마지막 인덱스 증가
// 현재 요소와 작은 요소들의 마지막 인덱스 위치의 요소를 교환
swap(array, i, j);
}
}
// 피벗을 작은 요소의 다음 위치에 놓기
swap(array, i + 1, high);
return i + 1; // 피벗의 최종 인덱스 반환
}
// 배열의 두 요소를 교환하는 메서드
private static void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
System.out.printf("(%d,%d) swap 후: %s\n",i,j,Arrays.toString(arr));
}
// 메인 메서드
public static void main(String[] args) {
int[] array = { 8,4,3,1,6,7,11,9,2,10,5 }; // 정렬할 배열
System.out.println("정렬 전: " + Arrays.toString(array)); // 정렬 전 배열 출력
quickSort(array, 0, array.length - 1); // 퀵 정렬 호출, 대상배열,시작위치,끝위치
System.out.println("정렬 후: " + Arrays.toString(array)); // 정렬 후 배열 출력
}
}
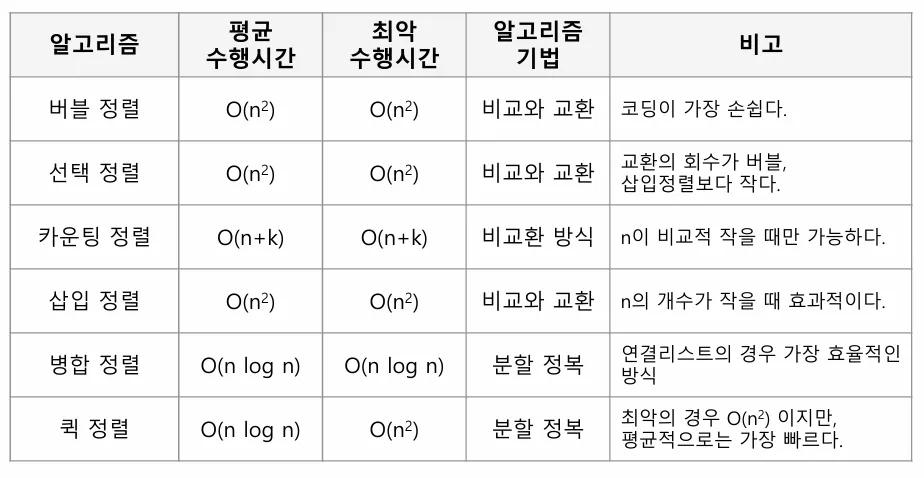
정렬 알고리즘 비교
자바에서 가장 효율적인 정렬 API
- Arrays.sort() 및 Collections.sort()
- 내부적으로 Timsort 알고리즘 사용 (병합 정렬 + 삽입 정렬의 하이브리드).
- 평균 O(n log n)의 성능을 가짐.
배열 정렬 (Arrays.sort())
1
2
3
4
5
6
7
8
9
import java.util.Arrays;
public class SortExample {
public static void main(String[] args) {
int[] numbers = {5, 3, 8, 1, 2};
Arrays.sort(numbers); // 배열 정렬
System.out.println("정렬된 배열: " + Arrays.toString(numbers));
}
}
리스트 정렬 (Collections.sort())
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class SortExample {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
names.add("Charlie");
Collections.sort(names);
System.out.println("정렬된 리스트: " + names);
}
}
END
This post is licensed under CC BY 4.0 by the author.